

'강화학습'으로 스스로 인간 한계 뛰어넘어
허사비스 "신소재 설계 등 현실 문제 해결에 도움줄 것"
 |
| 이세돌 vs 알파고 대국(CG)<연합뉴스 제공> |
구글 딥마인드 팀이 10월 19일(한국시간) 과학 학술지 '네이처'를 통해 공개한 바둑 프로그램 '알파고 제로'는 인공지능이 인간 도움 없이 인간을 까마득하게 초월할 수 있는 잠재력을 현실화했다는 점에서 획기적이라는 평가를 받는다.
이번 연구가 단순히 바둑을 조금 더 잘 두는 프로그램이 나왔다는 정도를 훨씬 넘어서서, 과학계와 산업계의 비상한 관심을 끄는 것은 이 때문이다.
지금까지 인공지능 시스템은 주로 인간 전문가들의 결정을 따라하도록 만들어진 '지도학습 시스템'(supervised learning system), 즉 인간이 인공지능의 훈련을 감독하는 시스템이었다.
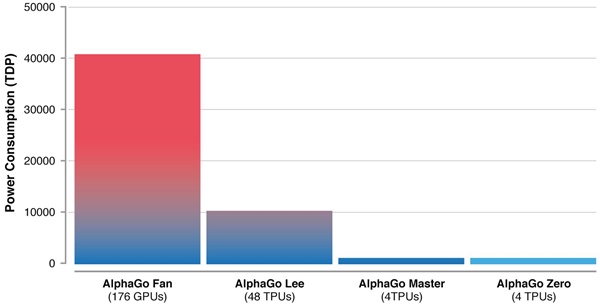 |
| 알파고 제로와 기존 알파고 버전의 컴퓨팅 파워를 비교한 그림. [DeepMind 제공] |
그러나 인간 전문가의 결정에 대한 데이터를 구하는 데 비용이 많이 들거나, 데이터를 믿을 수 없거나, 그런 데이터가 아예 없는 경우가 많다는 것이 구글 딥마인드 팀의 지적이다. 설령 신뢰할만한 데이터가 있더라도 인공지능 시스템이 인간이 만든 데이터에 의한 지도 하에 훈련을 받을 경우 이 탓에 인간의 한계를 뛰어넘지 못할 수도 있다.
이런 한계를 극복하기 위해 최근에는 '강화 학습'(reinforcement learning system)에 대한 연구가 이뤄지고 있다.
인간으로부터 배우지 않고 인공지능이 스스로 수
 |
| 데미스 허사비스 구글 딥마인드 공동창업자 겸 CEO [DeepMind 제공] |
많은 시행착오를 통해 요령을 터득하도록 하는 방법이다. 특히 믿을만한 인간 전문가가 아예 존재하지 않는 전혀 새로운 분야를 이런 방식으로 연구하는 데에 관심이 쏠린다.
강화학습 방식으로 만들어진 알파고 제로는 지금까지 나온 알파고 버전들 중 가장 강력하다. 구글 딥마인드 팀이 발표한 네이처 논문에는 알파고 제로에 앞서 개발돼 인간 기사들과 대국한 기존 버전의 알파고가 여럿 나온다.
딥마인드에 따르면 2015년 유럽 챔피언이었던 판 후이 二단을 이긴 버전은 '알파고 판(Fan)', 작년 이세돌 九단을 이긴 버전은 '알파고 리(Lee)', 올해 1월 온라인 대국 사이트에 등장해 인간 고수들을 60전 전승으로 꺾은 것은 '알파고 마스터(Master)'다. 이 중 알파고 마스터는 올해 5월 현 세계 랭킹 1위 커제 九단을 정식 대국에서 3대 0으로 물리쳐 눈물을 흘리게 만들었다.'
기존 최강 버전인 알파고 마스터와 이를 능가하는 알파고 제로의 기본 알고리즘과 아키텍처(설계 구조)는 똑같다. 차이는 '인간으로부터 배웠느냐, 아니냐'이고, 인간으로부터 배우지 않은 후자가 더욱 뛰어난 실력을 갖게 됐다.
알파고 마스터는 그 전 버전들과 마찬가지로 인간의 대국 기보 데이터로 훈련을 받았고 바둑을 두는 전략의 일부도 인간으로부터 입력받은 후에 이를 바탕으로 강화학습을 했다.
이와 달리 알파고 제로는 바둑의 기본 규칙만 아는 상태로 혼자 바둑을 두는 강화학습 방식만으로 인간으로부터의 가르침 없이 바둑의 이치를 깨우쳤다.
논문에는 실린 '엘로(Elo)' 방식 점수 비교도 실려 있다. 대개 프로 九단이 2천940점 이상으로 평가된다. 엘로 점수 차가 200점이면 승률 비가 75%대 25%에 해당한다. 또 366점 차는 90% 대 10%, 677점 차는 99% 대 1%, 800점 이상이면 사실상 100% 대 0%에 해당한다.'
알파고 제로의 엘로 점수는 5천185점이었고, 알파고 마스터가 4천858점으로 그 다음이었다. 알파고 리의 점수는 3천739점, 알파고 판은 3천144점이었다.
알파고 제로가 바둑을 가장 잘 두는 비결에 대해 이정원 한국전자통신연구원(ETRI) 선임연구원은 "인간이 만든 기존의 바둑 이론을 버렸기 때문"이라고 논평했다.
이 연구원은 "세 살 버릇 여든까지 간다는 속담은 인공지능에게도 들어맞는 것 같다. 사람의 기보는 인공지능에 오히려 나쁜 버릇을 들게 했다"라며 "백지 상태에서 시작한 알파고 제로는 불과 3일 만에 알파고 리를 따라 잡고, 한 달 만에 알파고 마스터의 한계도 넘어섰다"고 설명했다.
감동근 아주대 전자공학과 교수는 "이번 버전을 통해 적어도 바둑에 있어선 강화학습만으로 인공지능을 구현할 수 있음을 확인했으며, 심지어 이전 버전을 넘을 수 있음을 입증했다"고 연구의 의의를 설명했다.
아울러 알파고 제로는 컴퓨팅 파워도 크게 줄였다. 이세돌과 대결했던 알파고가 TPU(텐서프로세싱유닛) 48개를 쓴 반면, 알파고 제로는 4개로 구동한다. TPU는 인공지능에 특화돼 구글이 만든 칩이다.'
구글 딥마인드는 블로그 글에서 "알파고 제로는 새로운 지식을 발견하고, 통상적이지 않은 전략을 개발하는 한편 새로운 수를 창조했다"며 "우리는 인공지능의 이런 창조력을 보고 사람의 독창성을 배가할 수 있다고 확신했다"고 밝혔다.
데미스 허사비스 구글 딥마인드 공동창업자 겸 CEO는 "인공지능이 단백질 접힘(각 단백질에 고유한 접힌 구조가 만들어지는 과정)이나 신소재 설계 등 현실의 문제를 해결하는 데 혁신을 이뤄낼 수 있기를 희망한다"고 사례를 들어 설명했다.
인간의 직관으로는 문제 해결이 쉽지 않은 이런 분야에서 인공지능이 인간을 까마득하게 초월하는 능력을 발휘할 수 있으리라는 기대다.'
연합뉴스=노벨사이언스 science@nobelscience.co.kr
<저작권자 © 노벨사이언스, 무단 전재 및 재배포 금지>
 간단한 공정으로 이산화탄소 분리 성공
간단한 공정으로 이산화탄소 분리 성공







