

유민수 교수 연구팀, 차등 프라이버시 기술이 적용된 인공지능(AI) 반도체 개발
사용자 개인정보보호 등 인공지능 어플리케이션의 보안성 향상 기대
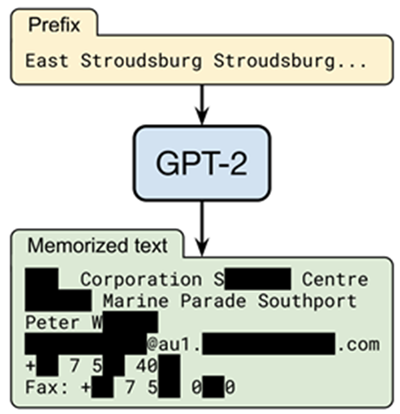 |
| 그림 1. 구글의 GPT-2 모델이 특정 입력에 대해 사용자 개인정보를 유출하는 사례 |
세계 최초 차등 프라이버시 기술의 성능 병목 구간을 분석해 해당 기술이 적용된 어플리케이션의 성능을 크게 시킬 수 있는 `차등 프라이버시 머신러닝을 위한 인공지능(AI) 반도체 칩'을 개발했다.
KAIST 전기 및 전자공학부 유민수 교수 연구팀이 개발한 인공지능 반도체는 외적 기반 연산기와 덧셈기 트리 기반의 후처리 연산기 등으로 구성돼 있으며, 현재 가장 널리 사용되는 인공지능 프로세서인 구글 TPUv3 대비 차등 프라이버시 인공지능 학습 과정을 3.6 배 빠르게 실행시킬 수 있고, 엔비디아의 최신 GPU A100 대비 10배 적은 자원으로 대등한 성능을 보인다고 연구팀 관계자는 설명했다. 또한 이번 개발을 통해서 기존 하드웨어의 한계로 널리 쓰이지 못했던 차등 정보보호 기술의 대중화에 도움을 줄 수 있을 것으로 기대된다.
빅데이터 및 인공지능 기술의 발전과 함께 구글, 애플, 마이크로소프트 등 클라우드 서비스를 제공하는 기업들은 전 세계 수십억 명의 사용자들에게 인공지능 기술을 기반으로 여러 가지 서비스(머신러닝 애즈 어 서비스, ML-as-a-Service, MLaaS)를 제공하고 있다. 이러한 서비스 중에는, 대표적으로 유튜브나 페이스북 등에서 시청자의 개별 취향에 맞춰 동영상 콘텐츠나 상품 등을 추천하는 `개인화 추천 시스템 기술(예- 딥러닝 추천 모델, Deep Learning Recommendation Model)' 이나, 구글 포토(Photo) 와 애플 아이클라우드(iCloud) 등에서 사진을 인물 별로 분류해주는 `안면 인식 기술 (예- 합성곱 신경망 네트워크 안면 인식, Convolutional Neural Network based Face Recognition)' 등이 있다.-
이와 같은 서비스는 사용자의 정보를 대량으로 수집해, 이를 기반으로 인공지능 알고리즘의 정확도와 성능을 개선한다. 이 과정에서 필연적으로 많은 양의 사용자 정보가 서비스 제공 기업의 데이터 센터로 전송되고, 민감한 개인정보나 파일들이 저장되고 사용되는 과정에서 정보가 유출되는 문제가 발생하기도 한다.
 |
| 유민수 교수팀이 개발한 개인정보 보호 인공지능 AI 반도체 가속기의 구조 모식도 |
또한 이러한 문제는 최근 주목받는 대형 인공지능 모델의 경우에 더 쉽게 발생하는 경향이 있으며, 실제 구글에서 사용하는 대화형 인공지능 모델인 GPT-2의 경우, 특정 단어들을 이야기했을 때 사용자의 개인정보 등을 유출하는 문제를 보였다. [참고1] 유사사례로서 국내에서 2020년 화제가 되었던 스캐터랩의 인공지능 챗봇 이루다의 경우에도 비슷한 문제가 불거진 적이 있다.
이에 애플, 구글, 마이크로소프트 등 빅 테크 기업에서는 `차등 프라이버시 (differential privacy)' 기술을 크게 주목하고 있다. 차등 프라이버시 기술은 학습에 사용되는 그라디언트(gradient, 학습 방향 기울기)에 잡음(노이즈)를 섞음으로써 인공지능 모델로부터 사용자의 개인정보를 유출하는 모든 종류의 공격을 방어할 수 있다.
하지만 이러한 장점에도 불구하고, 차등 프라이버시 기술 적용 시, 기존 대비 어플리케이션의 속도와 성능이 크게 하락하는 문제 때문에 아직까지 범용적으로 널리 적용되지는 못했다. 이는 차등 프라이버시 머신러닝 학습 과정이 일반적인 머신러닝 학습과 다른 특성을 보이고, 이로 인해 기존의 하드웨어에서 효과적으로 실행되지 않아 메모리 사용량, 학습 속도 및 하드웨어 활용도 (hardware utilization) 측면에서 비효율적이기 때문이다.
|
| 유민수 교수팀이 개발한 개인정보 보호 인공지능 AI 반도체 가속기의 구조 모식도 |
이번 연구는 지금까지는 없던 차등 프라이버시가 적용된 인공지능 반도체를 세계 최초로 개발했다는 점에서 의의가 있으며, 차등 프라이버시 인공지능 기술을 대중화해 인공지능 기반 서비스 사용자들의 개인정보를 보호하는 데에 큰 도움을 줄 수 있을 것으로 보인다. 또한, 가속기의 성능 향상은 인공지능 연구 효율을 높여 차등 프라이버시 인공지능 모델의 정확도 개선에도 기여할 것으로 보인다.
KAIST 전기및전자공학부 박범식, 황랑기 연구원이 공동 제1 저자로, 윤동호, 최윤혁 연구원이 공동 저자로 참여한 이번 연구는 미국 시카고에서 열리는 컴퓨터 구조 분야 최우수 국제 학술대회인 `55th IEEE/ACM International Symposium on Microarchitecture(MICRO 2022)'에서 오늘 10월 발표될 예정이다. (논문명 : DiVa: An Accelerator for Differentially Private Machine Learning)
한편 이번 연구는 한국연구재단, 삼성전자, 그리고 반도체설계교육센터 (IDEC, IC Design Education Center)의 지원을 받아 수행됐다.
□ 연구개요
연구 배경
기존의 데이터 센터에서 머신 러닝에 기반한 서비스를 제공하는 방법으로는 크게 그래픽 연산 장치 (e.g. NVIDIA GPU)를 사용하거나, 혹은 특정 목적으로 개발된 하드웨어 AI 반도체 (e.g. Google TPU) 를 사용하는 두 가지 방법이 널리 사용된다. 하지만 이 두 가지 방법 모두 차등 프라이버시와 같은 보안이 보장되는 알고리즘을 효과적으로 실행시키는데 적합하지 않기 때문에, 메모리 사용량, 머신 러닝 모델의 학습 속도 등에서 큰 성능 하락을 가져온다. 이는 차등 프라이버시가 적용된 머신 러닝 학습 과정은 기존의 머신 러닝과는 다른 특성을 보이기 때문이다.
차등 프라이버시 기반 머신 러닝 모델의 학습 과정에서는 학습 성능 향상과 지연시간 단축을 위해 기존에 널리 쓰이는 배치 기반의 확률적 경사 하강법 (Per-batch stochastic gradient descent) 을 사용하지 않고, 개별 데이터에 대한 보안성 향상을 위해 샘플 기반의 경사 (Per-sample gradient) 를 필요로 한다. 또한 샘플 기반의 경사 하강법을 통해서 도출한 각 가중치의 경사도의 L2 평균 값을 구하고, 이를 특정 값에 기반하여 해당 값을 넘는 경우, 절삭을 하여 하나로 합치는 과정을 거친다. 또한 최종적으로는 구해진 값에 일정 노이즈를 섞게 된다. 이 전체의 과정을 차등 프라이버시 경사 하강법이라고 부르며, 이는 높은 병렬성을 보이는 배치 기반의 학습법 대비 수십 배의 지연시간 증가와 메모리 요구량 증가를 야기한다. 또한 대부분의 그래픽 연산 장치나, 하드웨어 AI 반도체 가속기는 높은 병렬성을 바탕으로 배치 기반의 확률적 경사 하강법에 최적화 되어 있기 때문에, 일반적으로 널리 쓰이는 하드웨어의 효용성과 자원 활용도를 큰 폭으로 감소시킨다.
2. 연구 내용
본 연구에서는 샘플 기반의 경사 하강법에 최적화된 연산기 설계와 더불어, 차등 프라이버시 경사 하강법의 전 과정을 가속시킬 수 있는 AI 반도체 구조를 제안한다. 해당 AI 반도체 가속기의 구조는 아래와 같다. (그림 1) 연구진이 제안하는 AI 반도체 가속기는 연산을 지원하는 부분과 실제 연산이 이루어지는 부분으로 나뉘어져 있으며, 연산을 지원하는 부분으로서는 그림에서 검정색으로 표시된 행렬들을 저장하는 저장공간, 그리고 DRAM 과 가속기 간의 데이터 교환을 관장하는 메모리 접근기 (DMA unit), 행렬의 연산 방향을 결정하는 방향 배열기 (transpose unit) 가 있다. 또한 실제 연산이 이루어지는 부분으로는 샘플 경사 하강법에서 주로 등장하는 비정형 행렬곱을 가속하기 위한 연산기 배열 (GEMM unit), 그리고 연산기 배열의 결과 값들을 후처리 하는 후처리 연산기 (post-processing) 가 있다.
해당 가속기는 예측 실험 결과 기존 Google TPUv3 대비 차등프라이버시 머신 러닝 학습 전 과정을 3.6 배 가속 시킬 수 있으며, NVIDIA 의 GPU A100 대비 10배 적은 자원으로도 대등한 성능을 보이는 것으로 관측되었다.
3. 기대 효과
본 AI 반도체는 다양한 분야에서 이미 적용되어 쓰이고 있는 차등 프라이버시 알고리즘을 가속하는 가속기이다. 본 연구의 가속기는 차등 프라이버시 머신 러닝의 학습 전 과정을 가속화 할 수 있기 때문에, 기존에 하드웨어의 한계로 더 널리 쓰이지 못했었던 차등 프라이버시 기술의 대중화에 큰 도움을 줄 수 있다. 또한 기존에 차등 프라이버시 기술의 단점으로 제시되었던 프라이버시가 지켜지지 않은 일반 머신 러닝 학습보다 정확도가 떨어진 다는 점 또한 본 가속기로 기존 대비 더 빠른 학습 속도를 가져갈 수 있기 때문에, 더 복잡한 차등 프라이버시 알고리즘을 적용해 볼 수 있는 가능성이 있다. 그리고 본 가속기는 기존의 일반 머신 러닝 학습 알고리즘 또한 효과적으로 실행 할 수 있기 때문에, 기존의 데이터 센터에서 굉장히 높은 적용성을 보인다. 이러한 효과와 장점들로 개인정보 보호 머신 러닝 (Privacy-preserving ML) 의 상용화를 앞당길 수 있으며, 전체 데이터 센터의 비용 절감에도 도움을 준다.
KAIST 홍보실 제공
□ 그림 설명
■유민수 교수 이력사항
□ 인적사항
○ 소 속 : KAIST
○ 2014년 University of Texas at Austin 박사 (컴퓨터공학)
○ 2009년 KAIST 석사 (전기 및 전자공학)
○ 2007년 서강대학교 학사 (전자공학)
□ 경력사항
○ 2019년~현재 : KAIST AI대학원 겸임교수
○ 2018년~현재 : KAIST 전기및전자공학부 교수
○ 2017~2018년 : POSTECH 컴퓨터공학과 교수
○ 2014~2017년 : NVIDIA Research
- Senior Research Scientist (2017.02 ~ 2017.05)
- Research Scientist (2014.05 ~ 2017.02)
노벨사이언스 science@nobelscience.co.kr
<저작권자 © 노벨사이언스, 무단 전재 및 재배포 금지>
 간단한 공정으로 이산화탄소 분리 성공
간단한 공정으로 이산화탄소 분리 성공







